Filebeat
filebeat就是beats 的一员,目前beat可以发送数据给Elasticsearch,Logstash,File,Console四个目的地址。
filebeat 是基于原先 logstash-forwarder 的源码改造出来的。换句话说:filebeat 就是新版的 logstash-forwarder,也会是 ELK Stack 在 shipper 端的第一选择。
以下主要介绍下filebeat。
汇总、“tail -f” 和搜索:
启动 Filebeat 后,打开 Logs UI,直接在 Kibana 中观看对您的文件进行 tail 操作的过程。通过搜索栏按照服务、应用程序、主机、数据中心或者其他条件进行筛选,以跟踪您的全部汇总日志中的异常行为。
性能稳健,不错过任何检测信号:
无论在任何环境中,随时都潜伏着应用程序中断的风险。Filebeat 能够读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断前停止的位置继续开始。
Filebeat 让简单的事情简单化:
Filebeat 内置有多种模块(auditd、Apache、NGINX、System、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。
之所以能实现这一点,是因为它将自动默认路径(因操作系统而异)与 Elasticsearch 采集节点管道的定义和 Kibana 仪表板组合在一起。不仅如此,数个 Filebeat 模块还包括预配置的 Machine Learning 任务。
容器就绪和云端就绪:
正在对所有内容进行容器化,或者正在云端环境中运行?通过 Elastic Stack,可以轻松地监测容器和云服务。在 Kubernetes、Docker 或云端部署中部署 Filebeat,即可获得所有的日志流:
信息十分完整,包括日志流的 pod、容器、节点、VM、主机以及自动关联时用到的其他元数据。此外,Beats Autodiscover 功能可检测到新容器,并使用恰当的 Filebeat 模块对这些容器进行自适应监测。
不会导致您的管道过载:
当将数据发送到 Logstash 或 Elasticsearch 时,Filebeat 使用背压敏感协议,以应对更多的数据量。如果 Logstash 正在忙于处理数据,则会告诉 Filebeat 减慢读取速度。
一旦拥堵得到解决,Filebeat 就会恢复到原来的步伐并继续传输数据。
输送至 Elasticsearch 或 Logstash,在 Kibana 中实现可视化:
Filebeat 是 Elastic Stack 的一部分,因此能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。
无论您要使用 Logstash 转换或充实日志和文件,还是在 Elasticsearch 中随意处理一些数据分析,亦或在 Kibana 中构建和分享仪表板,Filebeat 都能轻松地将您的数据发送至最关键的地方。
Filebeat概览:
filebeat是转发和集中日志数据的轻量级输出。可以作为代理的服务器上安装,filebeat监视指定的日志文件或者位置,收集日志事件,将其转发给Elasticsearch或者Logstash进行索引。
但是filebeat是怎么工作的呢?当启动filebeat的时候,它会启动一个或多个输入监视你指定位置的日志文件。对于filebeat定位的每个日志文件,它都会启动一个harvester(收割机)。
每一个filebeat都会读日志文件中当前新写入的内容,并将日志数据发送给libbeat,libbeat聚合事件并将聚合数据发送给filebeat指定的输出。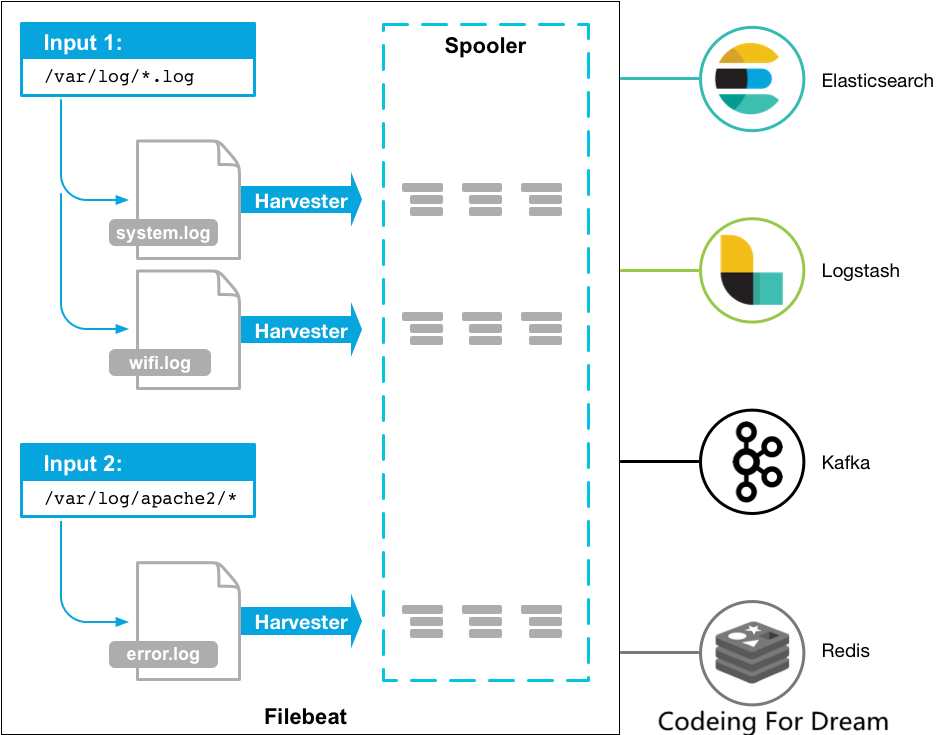
filebeat是基于libbeat框架。以下是架构设计。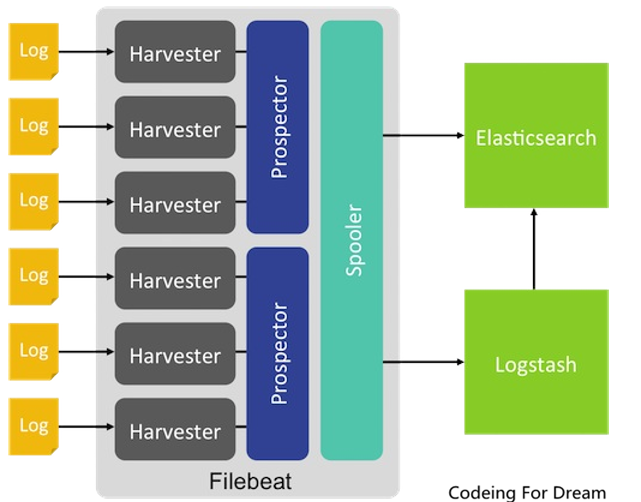
那filebeat是怎么工作的呢?
明白filebeat是如何工作的对于决定使用filebeat的哪些特定配置至关重要。
filebeat包含那个重要部分:输入input和收割者harvesters。这两部分协同工作去读取指定文件并输出到指定位置。
什么是收割者harvesters?
收割者是一行行的读取单个文件的内容,然后将读取的内容发送给输出。每一个收割者harvester启动自一个单独的文件。
收割者harvester负责关闭和开启一个文件,这意味着只要收割者harvester运行,文件描述符都是打开的。
如果一个文件被删除或者改名,收割者harvester仍旧保持对这个文件的读取。这有个副作用就是直到收割者harvester关闭前,磁盘的空间都为之保留着。默认情况下,filebeat都会保持文件打开状态直到达到关闭不活动状态。
什么是输出input?
输出input的职责是管理收割者harvester从哪里读数据。
如果输入类型是log,则输入会查找驱动上定义的与全局路径匹配的所有文件,并为每个文件启动一个收割者harvester,每一个输入都运行在自己的执行实例中。1
2
3
4
5filebeat.inputs:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.log
filebeat支持多种输入类型,每一种输入类型都可以被多次定义。日志输入可以检查每个文件是否需要启动收割者harvester。
fileBeat如何保持文件的状态?
filebeat保留每个文件的状态,并经常将状态刷新到注册表文件中的磁盘。状态用于记住harvester读取的最后一个偏移量,并确保将所有日志按行发送。
如果无法访问输出(如ElasticSearch或Logstash),则FileBeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
当filebeat运行时,每个输入的状态信息也保存在内存中。当filebeat重新启动时,注册表文件中的数据用于重建状态,filebeat将在最后一个已知位置继续运行harvester。
对于每个输入,filebeat都保持其找到的每个文件的状态。由于文件可以重命名或移动,因此文件名和路径不足以标识文件。对于每个文件,filebeat存储唯一的标识符,以检测是否是之前harvester过的文件。
如果涉及每天创建大量的新文件,就可能会发现注册表文件变得太大。看到注册表文件太大了吗?filebeat提供配置合理的参数方法解决这个问题。
fileBeat如何确保至少一次送达的?
filebeat保证事件将至少传递一次到配置的输出,并且不会丢失数据。FileBeat能够实现这种行为,因为它将每个事件的传递状态存储在注册表文件中。
在已定义的输出被阻止且尚未确认所有事件的情况下,FileBeat将继续尝试发送事件,直到输出确认已收到事件为止。
如果filebeat在发送事件的过程中关闭,它不会在关闭之前等待输出确认所有事件。当filebeat重新启动时,任何发送到输出但在filebeat关闭前未确认的事件都会再次发送。
这样可以确保每个事件至少发送一次,但最终可能会向输出发送重复的事件。通过设置shutdown_timeout选项,可以将filebeat配置为在关闭之前等待特定的时间。
FileBeat的至少一次送达有一个限制,包括日志轮换和删除旧文件。
如果日志文件被写入磁盘并旋转得比文件节拍处理的速度快,或者如果文件在输出时被删除不可用,数据可能会丢失。
原创不易,转载请注明出处。
加油!Coding For Dream!!
I never feared death or dying, I only fear never trying. –Fast & Furious