安装Filebeat
yum install filebeat
安装目录一览: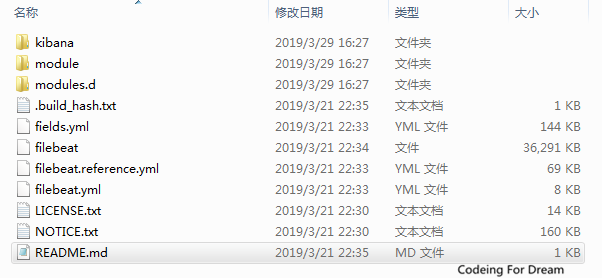
让我们分别介绍目录的功能:
kibana: 接入kibana时,其提供可视化配置功能
module module.d: 配置参数:用于快速启动功能
fields.yml: Filebeat提供针对不同组件,采集的参数名称 类型等
filebeat: 可执行文件
filebeat.reference.yml: Filebeat支持的参数手册,所有支持配置参数都在这
filebeat.yml: 启动Filebeat需要配置文件。后面我们会重点解析
配置Filebeat
配置文件:filebeat.yml
1.定义日志文件路径
对于最基本的Filebeat配置,你可以使用单个路径。例如:1
2
3
4
5filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
以上例子中,获取在/var/log/*.log路径下的所有文件作为输入,这就意味着Filebeat将获取/var/log目录下所有以.log结尾的文件。
也可以使用以下配置:/var/log//.log 抓取/var/log的子文件夹下所有的以.log结尾的文件。
目前不可能递归地抓取这个目录下的所有子目录下的所有.log文件。
也就是说假设配置的输入路径是/var/log//.log,如下图: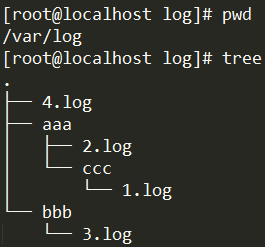
那么只会抓取到2.log和3.log,而不会抓到1.log和4.log。因为/var/log/aaa/ccc/1.log和/var/log/4.log不会被抓到。
2.如果你发送输出目录到kafka或者Elasticsearch(并且不用Logstash),那么设置IP地址和端口以便能够找kafka或者到Elasticsearch:
1 | output.elasticsearch: |
1 | output.kafka: |
3.如果你打算用Kibana仪表盘,可以这样配置Kibana端点:
1 | setup.kibana: |
4.如果你的Elasticsearch,kafka和Kibana配置了安全策略,那么在你启动Filebeat之前需要在配置文件中指定访问凭据。例如:
1 | output.elasticsearch: |
配置Filebeat以使用Logstash
如果你想使用Logstash对Filebeat收集的数据执行额外的处理,那么你需要将Filebeat配置为使用Logstash。1
2output.logstash:
hosts: ["127.0.0.1:5044"]
以上配置实现日志导入到指定模块elasticsearch/kafka的基本配置了。Filebeat又有哪些特殊参数?如何实现特色的需求哪?
Filebeat的输出
起输出数据的格式是json,类似这样:1
2
3
4
5
6
7
8
9
10
11{
"@timestamp": "2018-12-18T08:33:01.604Z", #采集时间 UTC
"@metadata": {....}, #描述beat的信息
"message": "日志内容", ### 数据主体
"source": "/var/log/run.log", #数据来源
"prospector": { "type": "log"},
"input": {"type": "log" }, #数据类型
"beat": {.... },
"host": {.... }, #系统信息 ip 系统版本 名称等
"offset": 244 #偏移
}
输出数据格式除包含数据主体 message 外,还包括部分附加信息。对于不需要信息,如何进行过滤和转换?这涉及Filebeat不算强大的数据过滤功能。
Filebeat数据过滤
过滤内容
exclude_lines: [‘^INFO’] #exclude_lines关键字排除包含内容INFO
include_lines: [‘^ERR’, ‘^WARN’]
exclude_files: [‘.gz/pre>] #排查压缩文件
multiline.pattern: ^[ #内容拼接,用户异常堆栈输出多行 拼接成一条过滤内容和内容拼接,需要日志的格式是json,否则不生效
过滤 json 中输出字段
Filebeat提供类似管道功能的处理器(processors),来指定生成字段,如下形式。
event -> filter1 -> event1 -> filter2 ->event2 …
每次数据采集是一个事件,每个filter是一个处理器。让我们自己定义一个处理器,如下:1
2
3
4
5processors:
-drop_fields:
when:
has_fields:['source']
fields:["input_type"]
功能:过滤器功能删除字段(drop_fields),条件是当存在source字段时,删除input_type字段。
在Elasticsearch中加载索引模板
默认情况下,如果启用了Elasticsearch输出,Filebeat会自动加载推荐的模板文件fields.yml,可以将filebeat.yml配置文件中的默认值更改为:
setup.template.name: “your_template_name”
setup.template.fields: “path/to/fields.yml”
覆盖现有模板:
setup.template.overwrite: true
禁用自动模板加载:(如果禁用自动模板加载,则需要手动加载模板)
setup.template.enabled: false
要手动加载模板,请运行setup命令。需要连接到Elasticsearch。如果启用了Logstash输出,则需要临时禁用Logstash输出并使用-E选项启用Elasticsearch。此处的示例假定已启用Logstash输出。
如果已启用Elasticsearch输出,则可以省略-E标志。1
filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
启动
启动kafka
./kafka-server-start.sh –zookeeper localhost:2181
使用Elasticsearch启动
/usr/local/programs/elasticsearch/elasticsearch-6.3.2/bin/elasticsearch
启动Kibana
/usr/local/programs/kibana/kibana-6.3.2-linux-x86_64/bin/kibana
设置dashboard
./filebeat setup –dashboards
启动Filebeat
./filebeat -e -c filebeat.yml -d “publish”
浏览器访问 127.0.0.1:5601
关于以上配置这部分。更全的可以参考Filebeat官网配置
filebeat提供的过滤功能挺有意思的,更全的可以参考Filebeat官网过滤使用语法
原创不易,转载请注明出处。
加油!Coding For Dream!!
I never feared death or dying, I only fear never trying. –Fast & Furious